
Token Myth
Stop Counting Tokens. Start Counting Tasks.

There’s a lot of chatter right now about “how many dollars of tokens I burned on Model A” versus “how many tokens I burned on Model B.” Firms are even asking employees to hit a certain spend or token quota per month. But this framing is broken — and it’s leading to a bragging game instead of a real productivity conversation.
The metric that actually matters isn’t $ per token. It’s $ per task. Here’s why.
1/ $ per Token — The Number Everyone Quotes
Most people access coding models through subscriptions — $20/month at the entry level, $200/month at the pro tier for most providers. But subscription plans don’t tell you how many tokens you actually burn.
So let’s use API pricing ($ per input token, $ per output token) as a proxy:
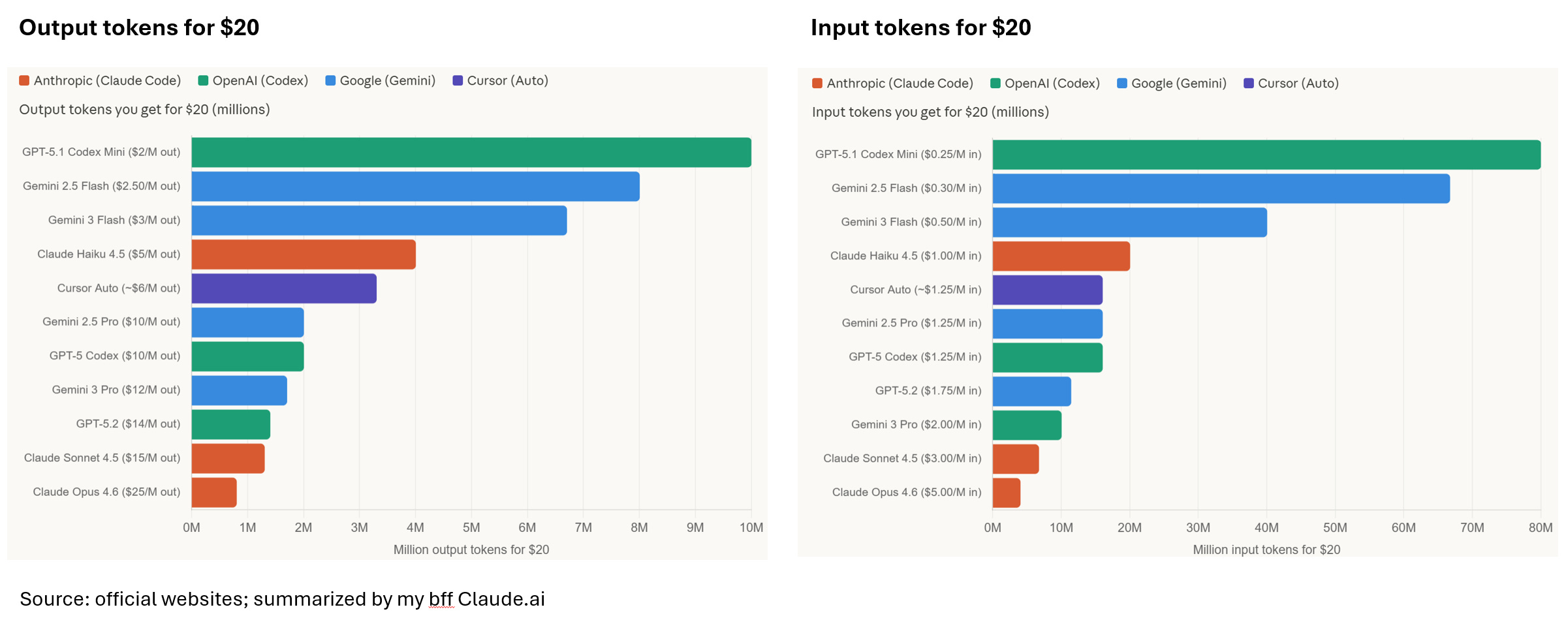
Looking at this, you might conclude that Claude Opus 4.6 is 12–80x more expensive than GPT-5.1 Codex Mini. But that conclusion is wrong. Here’s why.
2/ Token per Task — The Hidden Variable
Do different models consume different token counts for the same prompt? Yes — significantly. And this is the part that makes naive $/MTok comparisons misleading.
There are three layers of difference:
Tokenizer differences (minor, ~5–15% variance). OpenAI, Anthropic, and Google each use different tokenizers. The same code file might be 1,000 tokens on one platform and 1,100 on another. For code specifically, the gap is smaller than for natural language because code is more standardized. This isn’t the big driver.
Output verbosity (major, 2–5x variance). This is where it gets real. For the same “refactor this function” prompt, a more capable model like Opus or GPT-5.2 might produce a tight 200-line solution, while a cheaper model produces 400 lines of verbose, less elegant code — or worse, produces a wrong answer that requires follow-up turns (burning more input tokens re-sending context each time). Conversely, smarter models sometimes over-explain with comments and documentation, inflating output tokens. There’s no universal rule — it depends on the specific task and prompt.
Hidden thinking tokens (massive, 3–10x the bill). This is the sleeper cost. Models with “extended thinking” or “reasoning” modes — Claude’s extended thinking, OpenAI’s o-series, Gemini’s thinking mode — burn output tokens internally on chain-of-thought that you never see but still pay for. A request that produces 500 visible output tokens might actually consume 5,000 output tokens once you include the thinking budget. These thinking tokens are billed as output tokens at standard rates (MetaCTO). This alone can 3–10x your effective output cost without you realizing it.
Context accumulation (major for agentic coding). Tools like Claude Code and Codex work in multi-turn agentic loops — each step re-sends the growing conversation history plus file contents as input. A 10-step coding task might start at 5K input tokens and end at 80K+ by the final step. This is why Anthropic reports average Claude Code usage around $6/dev/day (Apiyi.com Blog) — it’s not one prompt, it’s dozens of agentic turns with ballooning context. Prompt caching helps significantly here: cache reads cost only 10% of the standard input price, saving up to 90% (MetaCTO).
3/ $ per Task — The Metric That Actually Matters
$/MTok is the unit cost. But the total tokens consumed per task varies so much across models that a model charging 2x per token might actually be cheaper per completed task — if it gets the answer right in fewer turns.
The real metric is cost per successfully completed coding task. And that’s model-quality-dependent, which is exactly why nobody publishes that number cleanly.
All the firms mandating a certain monthly AI spend should stop treating token burn as the KPI. Instead, ask your developers which models are the most efficient in terms of $ per task. They’re the ones actually running these tools day in, day out. They know everything.
Jensen “a $500k developer should burn $250k tokens (in the future)”.