
Open Source Models

A few thoughts on the model landscape:
Models need to be either great or cheap. You have to win on one end of the spectrum. Everything in the middle will get competed away.
We will see consolidation in both camps: the “great” camp and the “cheap” camp. People call DeepSeek the “death threshold”: if your model is only on par with or marginally better than DeepSeek, you won’t survive. DeepSeek is insanely cheap.
Model routing becomes a must. routing between “great” and “cheap” models, with tasks assigned to the right model to maximize performance per $.
The key question is whether cheap models cross the “good enough” line. The bear case for frontier models is that once cheap models are good enough, most users will be satisfied. I disagree. I think demand for frontier intelligence will never be fully satisfied. There will be durable demand at both ends of the market.
The GLM / China model fear is worth tracking, but not overstating yet. GLM is very chip constrained. It is mainly available through Together, Fireworks, and similar providers, not broadly across public clouds. I would track two things: 1) availability, and 2) the quality gap versus OpenAI and Anthropic. That will determine the real impact over time.
Token pricing can be misleading. If two models are similar and the price gap is 50%, that gap can easily be erased by infrastructure and token efficiency (one can use 2x the tokens to complete the same task). Comparing “input/output price per million tokens” alone is often deceptive.
Cheap models and the supply chain around them are underrated. (aka the China AI)
On-prem vs. cloud really shouldn’t have this much debate... I agree with the point here: if it takes $20k of hardware to run GLM 5.2 and you only break even after 5.5 years of 24/7 utilization, cloud still wins. Cloud compute remains more token-efficient per total cost dollar than local compute.
 Max Weinbach@mweinbachThe minimum to run the model is ~$20K in hardware and you get ~20 tok/s out ~$20K gets you around 34.6B tokens at a 12:1 input to output ratio assuming good token caching If you ran the hardware 24/7, it would take roughly 5.5 years to break even
Max Weinbach@mweinbachThe minimum to run the model is ~$20K in hardware and you get ~20 tok/s out ~$20K gets you around 34.6B tokens at a 12:1 input to output ratio assuming good token caching If you ran the hardware 24/7, it would take roughly 5.5 years to break even Jordan Nanos @JordanNanosGLM 5.2 costs $1.40/4.40 per Mtok at 40 tok/sec and people seriously consider buying GPU rigs for it https://t.co/mbGQrTqkV110:21 PM · Jun 20, 2026 · 221K Views100 Replies · 45 Reposts · 1.1K Likes
Jordan Nanos @JordanNanosGLM 5.2 costs $1.40/4.40 per Mtok at 40 tok/sec and people seriously consider buying GPU rigs for it https://t.co/mbGQrTqkV110:21 PM · Jun 20, 2026 · 221K Views100 Replies · 45 Reposts · 1.1K Likes“Tokenmaxxing” and “Jevons paradox” . As with any frontier technology, moving from early adopters to mainstream adoption often requires a reset. Cheap models will expand the market.


I’ve been surveying builders on GLM 5.2’s actual performance - basically, “don’t trust the benchmark, listen to what builders actually think.”
Would love to hear any feedback from people who have hands-on experience working with GLM 5.2 or other open-source models. A few early thoughts:
Quality
The feedback has been surprisingly positive. Many people say GLM 5.2 is roughly at the level of Codex 5.5 medium-thinking for coding tasks.
The most common view is that it performs better on front-end tasks than back-end tasks. The pushbacks I’ve heard are:
It still lags on more complex problem-solving.
It can be weaker on generalization - especially when the task is meaningfully different from common patterns it has seen before.
Price
I’ve heard effective cost is somewhere around 20-35% of Opus 4.8, depending on the workload. That is cheaper, but not as dramatic as the headline 4-6x difference implied by input/output token list pricing. More on that below.
How to think about open-source models overall
Gavin Baker framed it well:
“Frontier captures 90% of value; open source carries 80% of tokens.”
Two things can be true at the same time. The majority of economic value may continue to accrue to frontier models - and so far, it clearly has. At the same time, the majority of tokens consumed globally may be served by open-source models - and that also seems increasingly true.
A good example is Harvey. They reportedly used proprietary legal data to do reinforcement learning and supervised fine-tuning on an open-source model with Fireworks, then used a router. The result was better outcomes than Opus 4.7 / 4.8 at lower cost. That feels like the likely future: frontier models still get used heavily, but a majority of tokens may increasingly shift to task-specific open-source models.
DeepSeek as the cost-performance floor
DeepSeek is still the real cost leader here. In some ways, it creates a “price-performance floor”: any model that is more expensive than DeepSeek needs to be materially better, or users may simply use DeepSeek and retry more often.
That said, builders do complain about DeepSeek on a few dimensions:
Quality can be unstable.
Outputs can be inconsistent across runs.
For the same task, it often has the highest retry rate.
Higher retry rates can generate more cached tokens, which can eat into the apparent cost advantage.
Pricing comparison
On paper, GLM is 4-6x cheaper than Claude Opus. But several things can distort the actual economics:
Cache hit rate - especially for cache-heavy agent loops.
Success rate / retry rate - if one model completes the task in one pass while another needs 2-3 additional rounds, token savings can disappear quickly.
Stability - closely related to retry rate. A cheaper model that fails more often may not actually be cheaper in production.
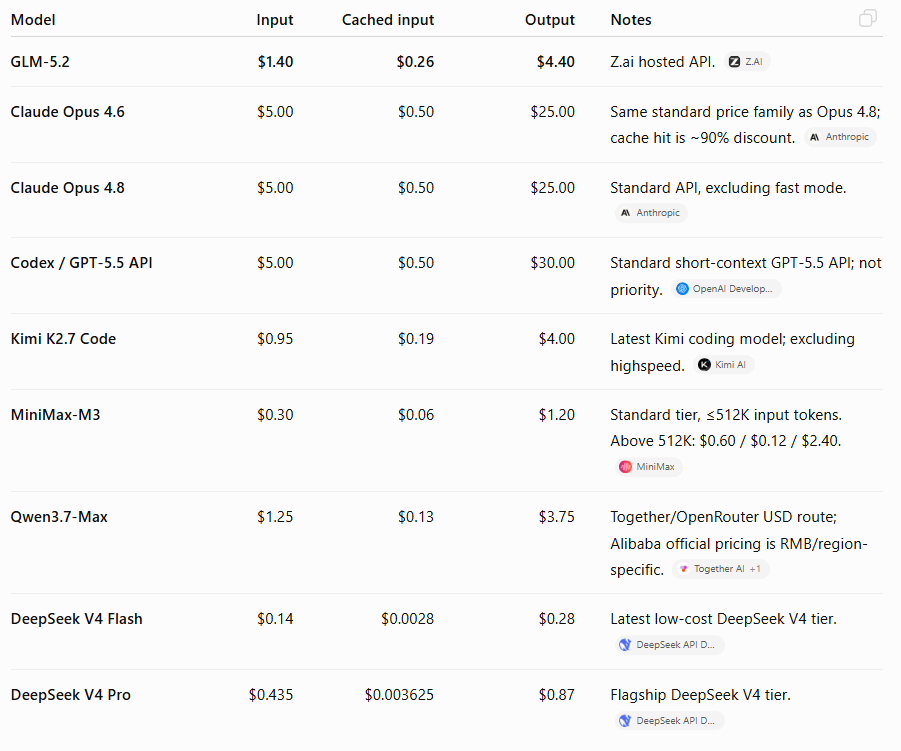
For a very cache-heavy agent loop, list-price comparisons can be misleading. The real question is not just input/output token price, but fully loaded cost per successful task.
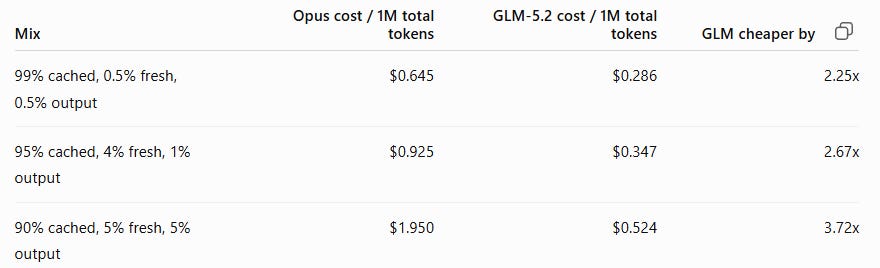
GLM availability & prices:

I agree the market has split into “as cheap as possible” vs “as clever as possible”
GLM 5.2 is clever, but to my taste DeepSeek writes better prose.
I have belief in OM in directional future. But can’t really test it without company enable it to really do side to side comparisons.
It’s also harder to do so because the agentic workflow already tailored so much to CC setup, I don’t even get time to Codex even. It’s not like no time to work on codex, but I can’t wait to keep iterating on CC as it’s not done yet.
Personal projects most of sonnet level is pretty easy because of the complexity and context limits.